[Infrastructure] Aptos Improvement Proposals 101 #1: An Overview of AIP-0 to AIP-10

Disclaimer: This post is for informational purposes only, and the author is not liable for the consequences arising from any investment or legal decision based on the information contained in this post. Nothing contained in this post suggests or recommends investing in any particular asset. Making any decisions based only on the information or content of this post is NOT advised.
TL;DR
- Aptos has introduced Aptos Improvement Proposals (AIPs) to enhance various aspects of the Aptos ecosystem, and currently, proposals up to AIP-35 are open for consideration.
- AIPs are intended to enhance the security, usability, and scalability of Aptos, as well as to improve the experience of developers and users, making the Aptos ecosystem more advanced.
[AIP-0] Aptos Improvement Proposals
TL;DR
- AIP stands for Aptos Improvement Proposals.
- You can discuss them within the community and propose an AIP standard if you think it’s a good idea.
What is AIP?
Aptos Improvement Proposals (AIPs) are standards that describe Aptos’ core blockchain protocols, Move, smart contracts, deployments, and operations.
How are they proposed and adopted?
AIPs are a set of processes that begin with community discussion within the Aptos community and foundation, followed by formal documentation. Other blockchains also have similar proposals, such as BIPs in Bitcoin and EIPs in Ethereum.
To propose an AIP, the first step is to present an idea and discuss it within the Aptos community. If there is supporting evidence, such as clear code or data, it can strengthen the proposal. Once the community provides positive feedback and a solid document is created, the process of creating a formal AIP can begin.
To propose an AIP on Aptos, locate the AIPs folder on the official Aptos GitHub and submit a pull request. Once submitted, it will be categorized as a Draft until all the necessary processes are completed and it is officially adopted. If you have a solid idea and a complete proposal, an Aptos AIP manager will review, comment, and either approve or reject it.
Two additional approvals are needed before the proposal can be officially adopted into the AIPs folder. Once adopted, the proposal will be shared for active discussion in the Aptos community. Feedback from the community will be taken into account and incorporated into the proposal. If significant changes are made, they will be deployed to the Aptos mainnet.
[AIP-1] Proposer Selection Improvements
TL;DR
- A proposer, determined each round, collects votes from the previous block and proposes the next block.
- To ensure fairness, the range of voter history used for selection is periodically updated to be more recent.
- It makes the proposer selection to be less predictable.
Proposer Selection Improvements
Let’s take a look at the first official proposal.
In Aptos, a new block is created and voted on in each round, and the “proposer” is responsible for collecting the votes from the previous block and proposing the next one. The selection criteria for the proposer are based on two factors:
- Ensuring fair distribution of work among all nodes and providing them with adequate rewards, and
- Prioritizing nodes that perform well.
How did it work before?
The previous proposer selection was based on the ProposerAndVoter and Leader Reputation algorithms, which analyzed the proposer’s voting and proposal history and choose a reputation_weight variable accordingly:
- If the proposer’s failure rate in previous rounds was above a certain threshold, the algorithm used failed_weight (currently set to 1).
- If the node had no significant impact in previous rounds, inactive_weight (currently set to 10) was used.
- Otherwise, the default active_weight (currently set to 1000) was used.
The reputation_weight was then scaled by staked_amount and used for random selection of the next proposer.
The threshold for viewing history is chosen so that it is not too large to respond quickly to changes, but not too small to maximize the viewing of history. For each block, Aptos obtains the signal of the proposer for only one node, whereas for two-thirds of the nodes, it obtains the signal of a single vote. This indicates that the window size for the proposer should be increased while maintaining a shorter window size for the voting.
That’s why this proposal is to upgrade the above-mentioned upgrade ProposerAndVoter algorithm.
ProposerAndVoterV2
The new proposer selection algorithm introduces two changes to the existing logic:
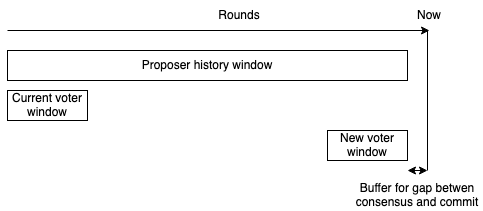
- Voter history window
The existing scope is as follows:
//Node performance history
(round - 10*num_validators - 20, round - 20)
//Voter history
(round - 10*num_validators - 20, round - 9*num_validators - 20)The last 20 rounds are removed as a buffer because there may be a delay.
The new scope looks like this:
//New voter history
(round - num_validators - 20, round - 20)You’ll see a slightly more recent history. This allows new validators, or nodes that have been interrupted and restarted, to be selected as proposers more quickly.
2. Pseudo-random selection
Currently, the cycle for randomized adoption is a tuple (epoch, round).
Although this allows for independent choices in each round, it also makes the process more predictable, which can make the network vulnerable to malicious attacks. As higher predictability suggests that it is easier for malicious actors to exploit the network, AIP 1 suggested changing the (epoch, round) to (root_hash, epoch, round) to reduce predictability.
[AIP-2] Multiple Token Changes
TL;DR
- Fixed several functions for developer convenience.
- Fixed several bugs to ensure token issuance is handled correctly.
Multiple Token Changes
This proposal contains 6 changes:
- token CollectionData mutation functions: Create a set of functions that can modify the TokenData fields depending on the mutability setting of the token.
- token TokenData metadata mutation functions: Create a series of functions that can change the CollectionData fields according to the mutability setting of the collection.
The proposed changes of 1–2 help developers organize their application logic in the direction they want to go by allowing them to mutate the TokenData and CollectionData.
3. A bug fix for collection supply underflow: fix a bug that can cause an underflow error when burning TokenData
4. Fix the order of events: During the process of token minting, the deposit events are currently placed in a queue before the mint events. This change puts the mint events first before the deposit event.
The proposed changes of 3–4 fix the errors for the correct execution of token contracts.
5. Make a public entry for transfer: Create an entry function that enables users to transfer tokens directly when they choose to opt-in for direct transfers.
This changes dApps to run functions without having to deploy their own contracts.
6. Fix the royalty issue: About 0.004% of the token has a royalty > 100%. This changes the denominator of these tokens to be larger than the numerator so that the royalty is always equal to or less than 100%.
This is to prevent the possibility of malicious tokens that could result in higher fees being charged than the actual token price.
[AIP-3] Multi-step Governance Proposal
TL;DR
- This proposal changes an on-chain proposal to contain multiple scripts so that the execution can be done in a single step.
Status quo
The Aptos on-chain governance is the process by which the Aptos community can propose, vote, and resolve issues to improve the Aptos blockchain. Currently, only one script can be included in a proposal. MoveVM, which runs Move, Aptos’ development platform, applies modifications at the end of a script only, so previous modifications to the script cannot be applied. However, many fixes require modifications to multiple scripts. This means that you can’t modify multiple scripts in a single upgrade, but must make multiple modifications to a single script.
Multi-step Governance Proposal
This proposal seeks to improve the governance process by allowing multiple scripts to be applied to a single on-chain proposal. In addition, it enables a single vote to modify multiple scripts within a single script, using a multi-step governance process. This approach can save the community time and effort while also ensuring that votes are applied in a specific order, making the overall process more efficient and effective.
Alternatives
- Keeping the Status Quo: Keeping the status quo requires too much time and effort, leaving the fixes prone to errors by not applying the changes in a specific order.
- Making a change to the MoveVM, which can read one at a time: Although we could make a VM-level change to apply changes at the end of each transaction, it would require too much effort into the system. While the smart contract changes essentially achieve the same thing more efficiently and easily.
Proposals
Making a multi-step proposal means chaining multiple scripts. Once chained, when a voter votes yes/no on the first chain, it is reflected in all chains. It is not possible to vote on only some of these chained scripts.
The chaining of scripts is done as follows:

When a script is executed, the previous script is hashed and passed to the next script. In effect, the on-chain proposal only includes the first script, but the hash for the following script is hashed in the first script, allowing it to be executed as a chain. A CLI is provided to check if the scripts are present and in the correct order.
The way multi-step proposals are made is no different than creating any proposal. The proposer only has to pass the hash parameter with the first script. The following is the proposed multi-step design:
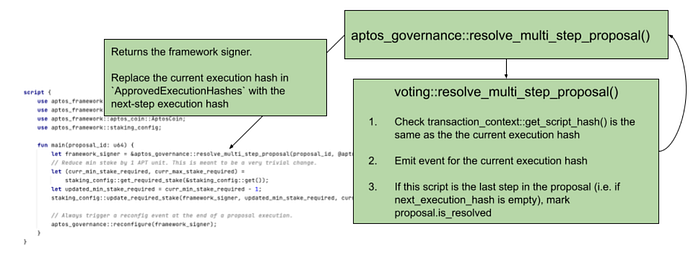
aptos_governance::resolve_multi_step_proposal()
//Returns a hash value for the following script.
voting::resolve()
/* checks that the hash of the current script is the same as the proposal’s current execution hash, update the proposal.execution_hash on-chain with the next_execution_hash, and emits an event for the current execution hash.
marks that the proposal is resolved if the current script is the last script in the chain of scripts.
.*/[AIP-4] Update Simple Map to Save Gas
TL;DR
- Revise the internal implementation of SimpleMap to lower gas prices while having minimal impact on Move and Public APIs.
Current System
Presently, SimpleMap utilizes a BCS-based logarithmic comparator to identify storage slots for data in a Vector. However, this approach is considerably more expensive than a straightforward linear implementation due to the need for BCS serialization and comparison. This is because converting to BCS is more time-consuming than the original comparison method, adversely impacting the gas prices.
Proposals
- Update the internal definition of ‘find’ from the current logarithmic implementation to a linear search across the vector.
- Replace the functionality within ‘add’ to call ‘vector::push_back’ and append new values, rather than inserting them into their sorted position. (because sorting takes a lot of time)
This changes the gas prices as the following if implemented:
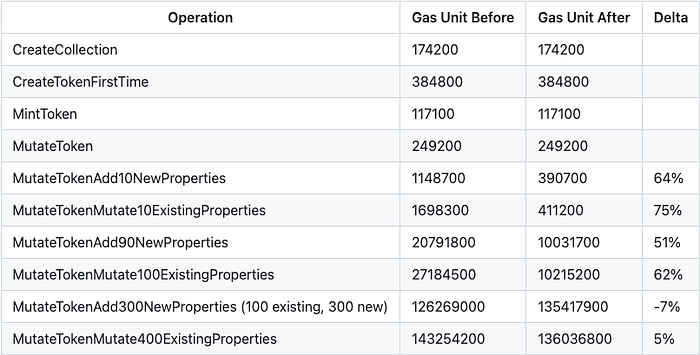
While the gas cost remains constant for a single token across the four categories, there is an upward trend in the number of tokens as you go down the list. When adding or updating 10 tokens, there was a reduction in the gas cost of 64% and 75%, respectively. When adding 90 tokens or updating 100 tokens, there was a significant decrease of 51% and 62%, respectively. However, when updating 600 tokens, the gas cost exceeded the maximum, making it impossible to track the gas cost changes.
The detailed code changes are as follows:
The changes are made to the ‘add’ and ‘find’ functions. In the previous code, when adding a value, it was sorted by swapping and inserting them into their swapped position. The updated code does not sort the values but appends them to the end of the vector.
// Before the proposed change
public fun add<Key: store, Value: store>(
map: &mut SimpleMap<Key, Value>,
key: Key,
value: Value,
) {
let (maybe_idx, maybe_placement) = find(map, &key);
assert!(option::is_none(&maybe_idx), error::invalid_argument(EKEY_ALREADY_EXISTS));
// Append to the end and then swap elements until the list is ordered again
vector::push_back(&mut map.data, Element { key, value });
let placement = option::extract(&mut maybe_placement);
let end = vector::length(&map.data) - 1;
while (placement < end) {
vector::swap(&mut map.data, placement, end);
placement = placement + 1;
};
}
// After the change
public fun add<Key: store, Value: store>(
map: &mut SimpleMap<Key, Value>,
key: Key,
value: Value,
) {
let maybe_idx = find_element(map, &key);
assert!(option::is_none(&maybe_idx), error::invalid_argument(EKEY_ALREADY_EXISTS));
vector::push_back(&mut map.data, Element { key, value });
}The following is a change in the find function.
Previously, it used a comparator to find a value logarithmically, but the new function uses a linear method that iterates over the value and returns if the stored value is the same as the value it is looking for.
// Before the proposed change
fun find<Key: store, Value: store>(
map: &SimpleMap<Key, Value>,
key: &Key,
): (option::Option<u64>, option::Option<u64>) {
let length = vector::length(&map.data);
if (length == 0) {
return (option::none(), option::some(0))
};
let left = 0;
let right = length;
while (left != right) {
let mid = left + (right - left) / 2;
let potential_key = &vector::borrow(&map.data, mid).key;
if (comparator::is_smaller_than(&comparator::compare(potential_key, key))) {
left = mid + 1;
} else {
right = mid;
};
};
if (left != length && key == &vector::borrow(&map.data, left).key) {
(option::some(left), option::none())
} else {
(option::none(), option::some(left))
}
}
// After the change
fun find_element<Key: store, Value: store>(
map: &SimpleMap<Key, Value>,
key: &Key,
): option::Option<u64>{
let leng = vector::length(&map.data);
let i = 0;
while (i < leng) {
let element = vector::borrow(&map.data, i);
if (&element.key == key){
return option::some(i)
};
i = i + 1;
};
option::none<u64>()
}[AIP-5] N/A
AIP-5 is Missing, Aptos!
This proposal is not found in the documentation. This appears to be an error in the proposal process.
[AIP-6] Delegation Pool for Node Operators
TL;DR
- Originally, you had to have 1M APT to stake and earn staking rewards, but now anyone can stake with a smaller amount of APT.
- This change is made possible by adding a delegation contract to the framework.
The current system
Originally, you had to have 1M APT to stake and earn rewards, but this was a huge barrier to entry, so Aptos proposed adding delegation contracts to encourage more people to join the Aptos ecosystem and allow everyone in the community to stake. The new system will allow anyone with any APT to participate in validator nodes and receive staking rewards, as long as the total APT in the delegation pool meets the minimum APT.
Delegators are rewarded in proportion to the amount they stake. Delegators can still use the same staking management controls (add_stake, unlock, withdraw, etc.) as before.
So what’s new?
According to the Aptos Delegation Pool documentation attached to AIP-6, the Stake-pool (SP) is the only way for validators to be rewarded for participating in the Aptos network, where all stake deposited is owned by a single account (SP owner) and no other delegators can participate. In addition, each aptos-epoch has a minimum volume that must be met to earn validator rewards. The total volume is divided into four states: active, pending_active, pending_inactive, and inactive. (See figure)
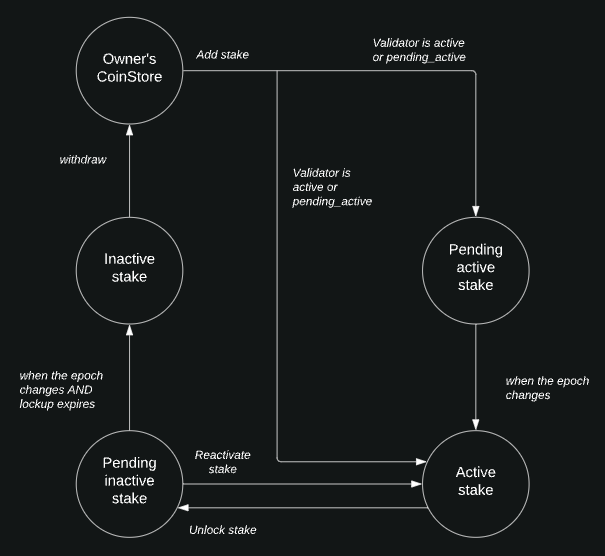
The state changes at the end of each Aptos-epoch unless it is in an inactive state, in which case the staking reward is automatically restaked.
Proposing Delegation Pool as a solution
The AIP-6 proposes to add a delegation pool (DP) on top of the existing SP in the Aptos staking framework. The DP will keep track of the staked volume and give delegates their initial deposit and staking rewards. All the necessary data is received from the calls passed on the SP interface. The DP records the delegator’s share of the total volume, not the absolute volume owned by the delegator. This is made possible by the data written to aptos_framework::pool_u64.
The DP must be an owning account of the SP and be eligible for epoch rewards. For this purpose, a resource account is created that is exclusively accessed by the DP. The stake states are handled differently in the staking protocol: in Epoch, only active and pending_inactive stakes produce rewards. Also, SPs can only directly withdraw inactive stakes. Once you’ve gone through the process above, you’ll be able to choose your favorite validator and delegate to them to receive staking rewards after the AIP-6 upgrade.
[AIP-7] Transaction Fee Distribution
TL;DR
- This is a proposal to increase meaningful throughput by redistributing transaction fees to validators instead of burning them.
The current system
Currently, all transaction fees within Aptos are burnt. This system does not incentivize users to prioritize higher-value transactions or use bigger blocks of transactions, resulting in lower throughput in the system. For example, validators can submit empty blocks and still get rewarded. To address these issues, we propose to distribute fees among validators. It works by storing the transaction fees for each block and redistributing them at the end of each epoch.
If transaction fees are redistributed to validators:
- The highest-value transactions are processed first and
- Further reinforce the benefits of parallel execution and increase system throughput.
Fee Burning Mechanism
There is an on-chain variable called burn_percentage. This variable determines what percentage of fees are burnt. Currently, all fees are burnt, so the burn_percentage is 100%. A burn_percentage of 0% means that all fees are collected and redistributed to the validators.
The amount of fees to be burnt, burnt_amount, and the amount to be collected, deposit_amount, are determined as follows:
burnt_amount = burn_percentage * transaction_fee / 100
deposit_amount = transaction_fee - burnt_amountFrom this, you might think that leaving burn_percentage at 0% and redistributing all fees is the best way to go, but there’s more to consider than that! You need to think about how this will affect your tokenomics, as it could cause major changes such as inflation.
Alternatives
- Distribute fees for every transaction.
Distributing fees per transaction has the following disadvantages:
a. Updating the balance of the validator for each transaction creates a read-modify-write dependency, which can be a bottleneck for parallel processing engines. This can be mitigated by implementing the balance as an “aggregator”, but this is not possible in the current system.
b. Validators are also rewarded in epochs, which some smart contracts rely on. If the validator’s balance is updated per transaction, the logic in the smart contract may be incompatible.
- Distribute fees every block.
a. To avoid the read-modify-write conflict from alternative 1-a, it was suggested that the fees could be collected in a variable using an “aggregator”, where each transaction in the block updates the aggregator value with the fee, and at the end of the block, the total value is distributed to the proposers.
b. However, this approach also does not solve 1-b, so the upgrade proposed by AIP-7 is essential.
How to implement?
- When executing a transaction within a block, the epilogue stores the gas fee in a special “aggregatable coin” on the system account. Unlike standard coins, changing the value of an aggregatable coin does not cause conflicts during parallel execution. The aggregatable coin can be “drained” to generate standard coins.
- In the first transaction of the next block, the collected gas fee is processed in the following way:
a. Drain the aggregator coins to get the sum of the transaction fees from the previous block.
b. Determine the percentage of fees to be burnt and distributed according to the formula
c. Burn the amount that will not be distributed.
d. Store the amount to be distributed in a special table stored on the system account. This creates or updates a map entry for the fees not yet distributed from the block proposer’s address.
e. Repeat the process in b for the next block and store the address of this block proposer so that the fee can be processed.
3. Distribute the fees collected at the end of the current epoch. Get the fee collected for each pending active and inactive validator and deposit it into the validator’s stake pool.
With this proposal, users will have control over which part of the transaction fee is collected and which part is burnt, and the numbers can be adjusted in the future through a governance proposal.
[AIP-8] Higher-Order Inline Functions for Collections
TL;DR
- Inline functions make it possible to implement higher-order functions in Move.
Limitations in Move
Aptos Move recently added the concept of “inline functions”. This feature allows you to implement functionality that is not available in regular Move functions. For example, you can use inline functions to define higher-order functions like ‘for_each’, ‘filter’, ‘map’, etc. that are commonly used in Rust, TypeScript, Java, and more.
Currently, Move doesn’t have an attribute that allows you to define an iterator type that understands which functions are available across different collection types, so this AIP-8 proposes to establish names and conventions for the most common functions.
Foreach
// Consume the Collection
public inline fun for_each<T>(v: vector<T>, f: |T|);
// Refer to an element
public inline fun for_each_ref<T>(v: &vector<T>, f: |&T|);
// Update an element
public inline fun for_each_mut<T>(v: &mut vector<T>, f: |&mut T|);Each function iterates over the collection in an order specific to that collection. For example, the second function, for_each_ref, can be used like this:
fun sum(v: &vector<u64>): u64 {
let r = 0;
for_each_ref(v, |x| r = r + *x);
r
}The above example is a code that implements a function called sum that calculates the sum. It declares a variable r, and iterates through the vector v using for_each_ref, applying |x| r = r + *x to each element. Finally, it returns the value of r which contains the sum of all elements.
Fold, Map, and Filter
The following are implementations of fold, map, and filter, which are higher-order functions that are commonly used when coding.
fold: Similar to “reduce”, this function combines all the elements in a collection into a single value. Typically, it requires two arguments: an initial value and a combining function. The combining function is executed on each element of the collection, and the results are accumulated in the initial value. The final result is the aggregated value.
map: A function that applies a function to each element of a collection and returns the result as a new collection. The returned collection has the same length as the original collection but consists of the transformed values. The function applied to each element in the collection must generate new values without modifying the original elements.
filter: A function that takes a collection and returns a new collection consisting only of elements that meet certain criteria. The criteria are defined by the predicate function applied to each element. If the predicate function returns true for an element, the element is included in the resulting collection; if it returns false, the element is not included.
// fold
public inline fun fold<T, R>(v: vector<T>, init: R, f: |R,T|R ): R;
// map
public inline fun map<T, S>(v: vector<T>, f: |T|S ): vector<S>;
// filter
public inline fun filter<T:drop>(v: vector<T>, p: |&T|bool) ): vector<T>;What higher-order functions can do
With this upgrade, it is possible to rewrite parts of the Aptos framework to be more auditable by eliminating the indiscriminate use of loops and replacing them with calls to higher-order functions. Move Prover can utilize these functions to fix poorly readable looping code, which is one of the most difficult parts of working with the prover. In the future, function parameters will also be supported in the Move VM.
[AIP-9] Resource Groups
TL;DR
- Resource groups allow you to group multiple resources together.
- This frees developers from performance considerations that previously frustrated them and makes Move more scalable.
The current situation and motivation
This AIP proposes resource groups for storing multiple Move resources together into a single storage slot.
It can be convenient for developers to add new resources as they develop. However, resources and structs are immutable once published, so adding new fields is the only way to add a new resource. Each resource in Aptos requires a storage slot, and each slot is a unique entry in the Merkle tree or authenticated data structure. (Each proof in the authenticated data structure takes up 32 * LogN bytes, where N is the total number of storage slots. If N = 1,000,000, this results in a 640-byte proof.)
With 1,000,000 slots in use, even the simple case of adding a new resource that contains only an event handle consumes about 680 bytes. The event handle only requires 40 bytes, but the new authenticated data proof consumes the remaining 640 bytes. Because authenticated data proofs are many times larger than the data being authenticated, there are additional costs associated with proof verification and authentication in addition to the capacity requirements.
Because resource groups allow you to store data dynamically, such as adding new events, new events can be added even after the resource group is created and incur a constant storage and execution cost regardless of the number of storage slots. This provides a convenient way to evolve data types and co-locate data from different resources.
Proposing resource groups
By placing data together in a single storage slot, resource groups specify which resources should be combined into a single storage slot through attributes encoded within the Move source file. Resource groups have no semantic impact on Move, only on storage organization.
In the storage layer, resource groups are stored as BCS-encoded BTreeMaps. Where the key is the complete BCS-encoded struct name (address::module_name::struct_name, e.g., 0x1::account::Account) and value is the BCS-encoded data associated with the resource.
Where BCS stands for “Binary Canonical Serialization”, which is the serialization format used by Move.
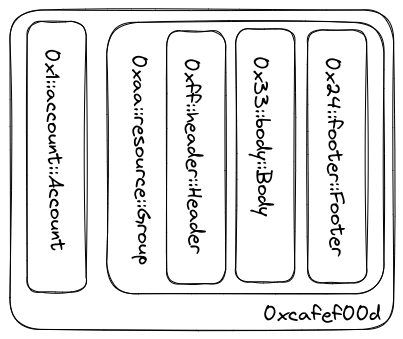
For example, the image above shows the data stored at the address 0xcafef00d. On the left, 0x1::account::Account represents the resource stored at this address. Grouped together on the right is a resource group.
Alternatives
- Using any in a SimpleMap: A way to write without changing Aptos-core is to use SimpleMap to store data, which has no caching and requires serialization of the object for both reads and writes. This makes it very difficult for APIs to access the data.
- Using templates
- Another alternative is to use templates, but the problem with this is that you can’t partially read data without knowing the template type. For example, in a resource group, a token can easily read an Object or Token resource, but in a template you need to read the Object<Token>.
Implementing Resource Groups frees developers from performance considerations that previously frustrated them and makes Move more scalable.
[AIP-10] Move Objects
TL;DR
- Revise and add clarity to Move’s object types to provide more explicit guidance to developers, saving them time and effort by reducing the need to search for information about object usage.
- Ensure that only the actions intended by using a particular object are performed on a resource, resulting in more secure and efficient code.
Proposing Move Objects
This AIP proposes a variety of Move Objects that can be used in development for global access to resources stored at a single address. They improve the user’s experience of accessing data by using a capability framework implemented by different accessors or reference that defines and deploys functionality to enable various operations.
The current system
Currently, the store feature within Move is used to store a struct in global storage. This makes the data globally accessible and can be stored at any address. While storing data using the store function provides flexibility in storing and accessing data, it can lead to the following issues:
- Access to the data is not always guaranteed. For example, if the data is stored in a user-defined resource, it can be confusing for users or developers to know where the data is stored.
- Using any, other data types can also be defined as one data type, which incurs additional costs because each access in Move requires deserialization. It can also cause confusion if API developers expect to change the type represented by a particular any field.
- Data can’t be composed recursively. Move currently has limitations on recursive data structures. There is also empirical evidence that real-world recursive data structures can lead to security vulnerabilities.
- Events can be emitted from an account that may not be related to the data, rather than from the data.
- Existing data cannot be easily referenced from entry functions. For example, supporting string validation requires many lines of code. Each key within a table can be very unique, which can get complicated to support within an entry function.
Move Objects
Object solves the above-mentioned problems:
- Developers can define the lifetime of their data, and data and its ownership model are globally accessible.
- Use tokens to personalize the core framework.
- Events can be emitted directly to improve the discoverability of events related to an object.
- Leverage resource groups to improve gas efficiency, avoid costly serialization, and enable deletability
<Capabilities>
Object <T>
- A pointer to an object (a wrapper around address)
- Abilities: copy, drop, store
ConstructorRef
- Provided when the object is created
- Can create other ref types
- Abilities: drop
DeleteRef
- Used when deleting an object
- Abilities: drop, store
ExtendRef
- Generates events and moves resources
- Abilities: drop, store
TransferRef
- Used to create a LinearTransferRef
- Can do ownership transfer
- Abilities: drop, store
LinearTransferRef
- Perform transfers
- Abilities: drop
Future Potential
This AIP has been updated to give developers more control over their resources. For example, let’s say you’re developing a game. You can implement features like LinearTransferRef to allow users to choose which items they want to receive in exchange for completing tasks. Alias<T> allows developers to reference specific modules when using them without having to declare the specific version of the module directly, making their code more efficient.
Closing
In this series, I discussed Aptos AIP-0 through AIP-10. Each subsequent AIP contains suggestions for specific issues that Aptos seeks to enhance, providing us with a clearer understanding of the team’s development roadmap and objectives. By reviewing these proposals, we can gain insights into the direction of the blockchain and its potential improvements.
Stay tuned for the next part of this series, where I will explore AIP-11 through AIP-20.

